Processeur
Cet article ne cite pas suffisamment ses sources (novembre 2007).
Si vous disposez d'ouvrages ou d'articles de référence ou si vous connaissez des sites web de qualité traitant du thème abordé ici, merci de compléter l'article en donnant les références utiles à sa vérifiabilité et en les liant à la section « Notes et références »
En pratique : Quelles sources sont attendues ? Comment ajouter mes sources ?

La puce d'un microprocesseur Intel 80486DX2 dans son boîtier (taille réelle : 12 × 6,75 mm).
Un processeur (ou unité centrale de traitement, UCT, en anglais central processing unit, CPU) est un composant présent dans de nombreux dispositifs électroniques qui exécute les instructions machine des programmes informatiques. Avec la mémoire, c'est notamment l'un des composants qui existent depuis les premiers ordinateurs et qui sont présents dans tous les ordinateurs. Un processeur construit en un seul circuit intégré est un microprocesseur.
L'invention du transistor en 1948 a ouvert la voie à la miniaturisation des composants électroniques. Car auparavant les ordinateurs prenaient la taille d'une pièce entière.
Les processeurs des débuts étaient conçus spécifiquement pour un ordinateur d'un type donné. Cette méthode coûteuse de conception des processeurs pour une application spécifique a conduit au développement de la production de masse de processeurs qui conviennent pour un ou plusieurs usages. Cette tendance à la standardisation qui débuta dans le domaine des ordinateurs centraux (mainframes à transistors discrets et mini-ordinateurs) a connu une accélération rapide avec l'avènement des circuits intégrés. Les circuits intégrés ont permis la miniaturisation des processeurs. La miniaturisation et la standardisation des processeurs ont conduit à leur diffusion dans la vie moderne bien au-delà des usages des machines programmables dédiées.
Sommaire
1 Histoire
2 Microprocesseurs
3 Fonctionnement
3.1 Composition d'un processeur
3.2 Classification des processeurs
3.3 Les opérations du processeur
4 Vitesse de traitement
5 Conception et implémentation
5.1 Le codage des nombres
5.2 Le signal d'horloge
5.3 Parallélisme
5.3.1 ILP : pipelining et architecture superscalaire
5.3.2 TLP : multithreading simultané et architecture multicœur
6 Notes et références
6.1 Notes
6.2 Références
7 Annexes
7.1 Articles connexes
7.2 Liens externes
Histoire |
Les premiers processeurs nécessitaient un espace important, puisqu'ils étaient construits à base de tubes électroniques ou de relais électromécaniques. Leur création a pour origine les travaux de John von Neumann qui répondaient aux difficultés liées à la reprogrammation de calculateurs comme l'ENIAC où il était nécessaire de recâbler le système pour faire fonctionner un nouveau programme. Dans cette architecture, une unité de contrôle se charge de coordonner un processeur (ayant accès aux entrées/sorties) et la mémoire. Tout cela a été décrit par un document intitulé « première ébauche d'un rapport sur l'EDVAC ».
Microprocesseurs |

Intel 80486DX2 microprocesseur en boîtier céramique PGA.
L'introduction du microprocesseur dans les années 1970 a marqué de manière significative la conception et l'implémentation des unités centrales de traitement. Depuis l'introduction du premier microprocesseur (Intel 4004) en 1971 et du premier microprocesseur employé couramment (Intel 8080) en 1974, cette classe de processeurs a presque totalement dépassé toutes les autres méthodes d'implémentation d'unité centrale de traitement. Les fabricants d'ordinateurs centraux (mainframe et miniordinateurs) de l'époque ont lancé leurs propres programmes de développement de circuits intégrés pour mettre à niveau les architectures anciennes de leurs ordinateurs et ont par la suite produit des microprocesseurs à jeu d'instructions compatible en assurant la compatibilité ascendante avec leurs anciens modèles. Les générations précédentes des unités centrales de traitement comportaient un assemblage de composants discrets et de nombreux circuits faiblement intégrés sur une ou plusieurs cartes électroniques. Les microprocesseurs sont construits avec un très petit nombre de circuits très fortement intégrés (ULSI), habituellement un seul. Les microprocesseurs sont implémentés sur une seule puce électronique, donc de dimensions réduites, ce qui veut dire des temps de commutation plus courts liés à des facteurs physiques comme la diminution de la capacité parasite des portes. Ceci a permis aux microprocesseurs synchrones d'augmenter leur fréquence de base de quelques mégahertz[1] à plusieurs gigahertz[2]. De plus, à mesure que la capacité à fabriquer des transistors extrêmement petits sur un circuit intégré a augmenté, la complexité et le nombre de transistors dans un seul processeur ont considérablement crû. Cette tendance largement observée est décrite par la loi de Moore, qui s'est avérée être jusqu'ici un facteur prédictif assez précis de la croissance de la complexité des processeurs (et de tout autre circuit intégré).
Les processeurs multi cœurs (multicores) récents comportent maintenant plusieurs cœurs dans un seul circuit intégré. Leur efficacité dépend grandement de la topologie d'interconnexion entre les cœurs. De nouvelles approches, comme la superposition de la mémoire et du cœur de processeur (memory stacking), sont à l'étude, et devraient conduire à un nouvel accroissement des performances. En se basant sur les tendances des dix dernières années, les performances des processeurs devraient atteindre le pétaFLOPS, vers 2010 pour les serveurs, et à l'horizon 2030 dans les PC.[réf. nécessaire]
En juin 2008, le supercalculateur militaire IBM Roadrunner est le premier à franchir cette barre symbolique du pétaFLOPS. Puis, en novembre 2008, c'est au tour du supercalculateur Jaguar de Cray. En avril 2009, ce sont les deux seuls supercalculateurs à avoir dépassé le pétaFLOPS.
En novembre 2015, pour la sixième fois consécutive, le supercalculateur chinois Tianhe-2 "milky way-2", développé par l'université nationale chinoise pour les technologies de défense, atteint la première place du classement semestriel mondial TOP500[3] des supercalculateurs avec 33,86 pétaFLOPS. En matière de record de performance, la tendance semble être au ralentissement depuis l'année 2008.
Tandis que la complexité, la taille, la construction, et la forme générale des processeurs ont fortement évolué au cours des soixante dernières années, la conception et la fonction de base n'ont pas beaucoup changé. Presque tous les processeurs communs d'aujourd'hui peuvent être décrits très précisément comme machines à programme enregistré de von Neumann. Alors que la loi de Moore, mentionnée ci-dessus, continue de se vérifier, des questions ont surgi au sujet des limites de la technologie des circuits intégrés à transistors. La miniaturisation des portes électroniques est si importante que les effets de phénomènes comme l'électromigration (dégradation progressive des interconnexions métalliques entraînant une diminution de la fiabilité des circuits intégrés) et les courants de fuite (leur importance augmente avec la réduction des dimensions des circuits intégrés ; ils sont à l'origine d'une consommation d'énergie électrique pénalisante), auparavant négligeables, deviennent de plus en plus significatifs. Ces nouveaux problèmes sont parmi les nombreux facteurs conduisant les chercheurs à étudier, d'une part, de nouvelles technologies de traitement telles que l'ordinateur quantique ou l'usage du calcul parallèle et, d'autre part, d'autres méthodes d'utilisation du modèle classique de von Neumann.
Fonctionnement |
Composition d'un processeur |

Schéma de principe d'un processeur 32 bits.
Un processeur n'est pas une unité de calcul. Cette dernière est incluse dans le processeur mais il fait aussi appel à une unité de contrôle, une unité d'entrée-sortie, à une horloge et à des registres.
Le séquenceur, ou unité de contrôle, se charge de gérer le processeur. Il peut décoder les instructions, choisir les registres à utiliser, gérer les interruptions ou initialiser les registres au démarrage. Il fait appel à l'unité d'entrée-sortie pour communiquer avec la mémoire ou les périphériques.
L'horloge doit fournir un signal régulier pour synchroniser tout le fonctionnement du processeur. Elle est présente dans les processeurs synchrones mais absente des processeurs asynchrones et des processeurs autosynchrones.
Les registres sont des petites mémoires internes très rapides, pouvant être accédées facilement. Un plus grand nombre de registres permettra au processeur d'être plus indépendant de la mémoire. La taille des registres dépend de l'architecture, mais est généralement de quelques octets et correspond au nombre de bit de l'architecture (un processeur 8 bits aura des registres d'un octet).
Il existe plusieurs registres, dont l'accumulateur et le compteur ordinal qui constituent la structure de base du processeur. Le premier sert à stocker les données traitées par l'UAL (l'unité de calcul arithmétique et logique), et le second donne l'adresse mémoire de l'instruction en cours d'exécution ou de la suivante (en fonction de l'architecture).
D'autres registres ont été ajoutés au fil du temps :
- le pointeur de pile : il sert à stocker l'adresse du sommet des piles, qui sont en fait des structures de données généralement utilisées pour gérer des appels de sous-programmes,
- le registre d'instruction : il permet quant à lui de stocker l'instruction en cours de traitement,
- le registre d'état : il est composé de plusieurs bits, appelés drapeaux (flags), servant à stocker des informations concernant le résultat de la dernière instruction exécutée,
- les registres généraux, qui servent à stocker les données allant être utilisées (ce qui permet d'économiser des allers-retours avec la mémoire).
Les processeurs actuels intègrent également des éléments plus complexes :
- plusieurs unités arithmétiques et logiques, qui permettent de traiter plusieurs instructions en même temps. L'architecture superscalaire, en particulier, permet de disposer des UAL en parallèle, chaque UAL pouvant exécuter une instruction indépendamment de l'autre ;
unité de calcul en virgule flottante (en anglais floating-point unit, FPU), qui permet d'accélérer les calculs sur les nombres réels codés en virgule flottante ;
unité de prédiction de branchement, qui permet au processeur d'anticiper un branchement dans le déroulement d'un programme afin d'éviter d'attendre la valeur définitive de l'adresse du saut. Il permet de mieux remplir le pipeline ;
pipeline, qui permet de découper temporellement les traitements à effectuer ;
mémoire cache, qui permet d'accélérer les traitements en diminuant les accès à la mémoire vive. Le cache d'instructions reçoit les prochaines instructions à exécuter, le cache de données manipule les données. Parfois un cache unifié est utilisé pour les instructions et les données. Plusieurs niveaux (levels) de caches peuvent coexister, on les désigne souvent sous les noms de L1, L2, L3 ou L4. Dans les processeurs évolués, des unités spéciales du processeur sont dévolues à la recherche, par des moyens statistiques et/ou prédictifs, des prochains accès à la mémoire vive.
Un processeur possède aussi trois types de bus :
bus de données, qui définit la taille des données pour les entrées–sorties, dont les accès à la mémoire (indépendamment de la taille des registres internes) ;
bus d'adresse, qui permet, lors d'une lecture ou d'une écriture, d'envoyer l'adresse où elle s'effectue, et donc définit le nombre de cases mémoire accessibles ;
bus de contrôle, qui permet la gestion du matériel, via les interruptions.
Classification des processeurs |
Un processeur est défini par :
- Son architecture, c'est-à-dire son comportement vu par le programmeur, liée à :
- son jeu d'instructions (en anglais instruction set architecture, ISA) ;
- la largeur de ses registres internes de manipulation de données (8, 16, 32, 64, 128) bits et leur utilisation ;
- les spécifications des entrées–sorties, de l'accès à la mémoire, etc.
- Ses caractéristiques, variables même entre processeurs compatibles :
- sa microarchitecture ;
- la cadence de son horloge exprimée en mégahertz (MHz) ou gigahertz (GHz) ;
- sa finesse de gravure exprimée en nanomètres (nm) ;
- son nombre de cœurs de calcul.
On classe les architectures en plusieurs grandes familles :
CISC (complex instruction set computer), choix d'instructions aussi proches que possible d'un langage de haut niveau ;
RISC (reduced instruction set computer), choix d'instructions plus simples et d'une structure permettant une exécution très rapide ;
VLIW (very long instruction word) ;
DSP (digital signal processor), même si cette dernière famille est relativement spécifique. En effet, un processeur est un composant programmable et est donc a priori capable de réaliser tout type de programme. Toutefois, dans un souci d'optimisation, des processeurs spécialisés sont conçus et adaptés à certains types de calculs (3D, son, etc.). Les DSP sont des processeurs spécialisés pour les calculs liés au traitement de signaux. Par exemple, il n'est pas rare de voir implémenter des transformées de Fourier dans un DSP ;
processeur softcore, est un circuit logique programmable et n'a plus du tout de fonction précablée contrairement à un DSP.
Les opérations du processeur |
Le rôle fondamental de la plupart des processeurs, indépendamment de la forme physique qu'ils prennent, est d'exécuter une série d'instructions stockées appelée programme.
Les instructions (parfois décomposées en micro-instructions) et les données transmises au processeur sont exprimées en mots binaires (code machine). Elles sont généralement stockées dans la mémoire. Le séquenceur ordonne la lecture du contenu de la mémoire et la constitution des mots présentés à l'ALU qui les interprète.
Le langage le plus proche du code machine tout en restant lisible par des humains est le langage d'assemblage, aussi appelé langage assembleur (forme francisée du mot anglais « assembler »). Toutefois, l'informatique a développé toute une série de langages, dits de « bas niveau » (comme le Pascal, C, C++, Fortran, Ada, etc.), « haut niveau » (comme le python, java, etc.), destinés à simplifier l'écriture des programmes.
Les opérations décrites ici sont conformes à l'architecture de von Neumann. Le programme est représenté par une série d'instructions qui réalisent des opérations en liaison avec la mémoire vive de l'ordinateur. Il y a quatre étapes que presque toutes les architectures de von Neumann utilisent :
Fetch, recherche de l'instruction.
Decode, interprétation de l'instruction (opération et opérandes).
Execute, exécution de l'instruction.
Writeback, écriture du résultat.

Le diagramme montre comment une instruction de MIPS32 est décodée.
La première étape, fetch (recherche de l'instruction), recherche une instruction dans la mémoire vive de l'ordinateur. L'emplacement dans la mémoire est déterminé par le compteur de programme (PC), qui stocke l'adresse de la prochaine instruction dans la mémoire de programme. Après qu'une instruction ait été recherchée, le PC est incrémenté par la longueur du mot d'instruction. Dans le cas de mot de longueur constante simple, c'est toujours le même nombre. Par exemple, un mot de 32 bits de longueur constante qui emploie des mots de 8 bits de mémoire incrémenterait toujours le PC par 4 (excepté dans le cas des branchements). Le jeu d'instructions qui emploie des instructions de longueurs variables comme l'x86, incrémentent le PC par le nombre de mots de mémoire correspondant à la dernière longueur d'instruction. En outre, dans des processeurs plus complexes, l'incrémentation du PC ne se produit pas nécessairement à la fin de l'exécution d'une instruction. C'est particulièrement le cas dans des architectures fortement parallélisées et superscalaires. Souvent, la recherche de l'instruction doit être opérée dans des mémoires lentes, ralentissant le processeur qui attend l'instruction. Cette question est en grande partie résolue dans les processeurs modernes par l'utilisation de caches et de pipelines.
La seconde étape, decode (interprétation de l'instruction), découpe l'instruction en plusieurs parties telles qu'elles puissent être utilisées par d'autres parties du processeur. La façon dont la valeur de l'instruction est interprétée est définie par le jeu d'instructions du processeur[note 1]. Souvent, une partie d'une instruction, appelée opcode (code d'opération), indique l'opération à effectuer, par exemple une addition. Les parties restantes de l'instruction comportent habituellement les opérandes de l'opération. Ces opérandes peuvent prendre une valeur constante, appelée valeur immédiate, ou bien contenir l'emplacement où retrouver (dans un registre ou une adresse mémoire) la valeur de l'opérande, suivant le mode d'adressage utilisé. Dans les conceptions anciennes, les parties du processeur responsables de l'interprétation étaient fixes et non modifiables car elles étaient codées dans les circuits. Dans les processeurs plus récents, un microprogramme est souvent utilisé pour l'interprétation. Ce microprogramme est parfois modifiable pour changer la façon dont le processeur interprète les instructions, même après sa fabrication.

Diagramme fonctionnel d'un processeur simple.
La troisième étape, execute (exécution de l'instruction), met en relation différentes parties du processeur pour réaliser l'opération souhaitée. Par exemple, pour une addition, l'unité arithmétique et logique (ALU) sera connectée à des entrées et une sortie. Les entrées contiennent les nombres à additionner et la sortie contient le résultat. L'ALU est dotée de circuits pour réaliser des opérations d'arithmétique et de logique simples sur les entrées (addition, opération sur les bits). Si le résultat d'une addition est trop grand pour être codé par le processeur, un signal de débordement est positionné dans un registre d'état.
La dernière étape, writeback (écriture du résultat), écrit les résultats de l'étape d'exécution en mémoire. Très souvent, les résultats sont écrits dans un registre interne au processeur pour bénéficier de temps d'accès très courts pour les instructions suivantes. Parfois, les résultats sont écrits plus lentement dans la mémoire vive pour bénéficier de codages de nombres plus grands.
Certains types d'instructions manipulent le compteur de programme plutôt que de produire directement des données de résultat. Ces instructions sont appelées des branchements (branch) et permettent de réaliser des boucles (loops), des programmes à exécution conditionnelle ou des fonctions (sous-programmes) dans des programmes[note 2]. Beaucoup d'instructions servent aussi à changer l'état de drapeaux (flags) dans un registre d'état. Ces états peuvent être utilisés pour conditionner le comportement d'un programme, puisqu'ils indiquent souvent la fin d'exécution de différentes opérations. Par exemple, une instruction de comparaison entre deux nombres va positionner un drapeau dans un registre d'état suivant le résultat de la comparaison. Ce drapeau peut alors être réutilisé par une instruction de saut pour poursuivre le déroulement du programme.
Après l'exécution de l'instruction et l'écriture des résultats, tout le processus se répète, le prochain cycle d'instructions recherche l'instruction suivante puisque le compteur de programme avait été incrémenté. Si l'instruction précédente était un saut, c'est l'adresse de destination du saut qui est enregistrée dans le compteur de programme. Dans des processeurs plus complexes, plusieurs instructions peuvent être recherchées, décodées et exécutées simultanément, on parle alors d'architecture pipeline, aujourd'hui communément utilisée dans les équipements électroniques.
Vitesse de traitement |
La vitesse de traitement d'un processeur est encore parfois exprimée en IPS (instructions par seconde) ou en FLOPS (opérations à virgule flottante par seconde) pour l'unité de calcul en virgule flottante. Pourtant, aujourd'hui, les processeurs sont basés sur différentes architectures et techniques de parallélisation des traitements qui ne permettent plus de déterminer simplement leurs performances. Des programmes spécifiques d'évaluation des performances (Benchmarks) ont été mis au point pour obtenir des comparatifs des temps d'exécution de programmes réels.
Conception et implémentation |
Le codage des nombres |
La manière dont un processeur représente les nombres est un choix de conception qui affecte de façon profonde son fonctionnement de base. Certains des ordinateurs les plus anciens utilisaient un modèle électrique du système numérique décimal (base 10). Certains autres ont fait le choix de systèmes numériques plus exotiques comme les systèmes trinaires (base 3). Les processeurs modernes représentent les nombres dans le système binaire (base 2) dans lequel chacun des chiffres est représenté par une grandeur physique qui ne peut prendre que deux valeurs comme une tension électrique « haute » ou « basse ».
Le concept physique de tension électrique est analogique par nature car elle peut prendre une infinité de valeurs. Pour les besoins de représentation physique des nombres binaires, les valeurs des tensions électriques sont définies comme des états « 1 » et « 0 ». Ces états résultent des paramètres opérationnels des éléments de commutation qui composent le processeur comme les niveaux de seuil des transistors.

Le microprocesseur 6502 en technologie MOS dans un boîtier dual in-line une conception très répandue.
En plus du système de représentation des nombres, il faut s'intéresser à la taille et la précision des nombres qu'un processeur peut manipuler nativement. Dans le cas d'un processeur binaire, un « bit » correspond à une position particulière dans les nombres que le processeur peut gérer. Le nombre de bits (chiffres) qu'un processeur utilise pour représenter un nombre est souvent appelé « taille du mot » (« word size », « bit width », « data path width ») ou « précision entière » lorsqu'il s'agit de nombres entiers (à l'opposé des nombres flottants). Ce nombre diffère suivant les architectures, et souvent, suivant les différents modules d'un même processeur. Par exemple, un processeur 8-bit gère nativement des nombres qui peuvent être représentés par huit chiffres binaires (chaque chiffre pouvant prendre deux valeurs), soit 28 ou 256 valeurs discrètes.
La taille du mot machine affecte le nombre d'emplacements mémoire que le processeur peut adresser (localiser). Par exemple, si un processeur binaire utilise 32 bits pour représenter une adresse mémoire et que chaque adresse mémoire est représentée par un octet (8 bits), la taille mémoire maximum qui peut être adressée par ce processeur est de 232 octets, soient 4 Go. C'est une vision très simpliste de l'espace d'adressage d'un processeur et beaucoup de conceptions utilisent des types d'adressages bien plus complexes, comme la pagination, pour adresser plus de mémoire que la taille du nombre entier le leur permettrait avec un espace d'adressage à plat.
De plus grandes plages de nombres entiers nécessitent plus de structures élémentaires pour gérer les chiffres additionnels, conduisant à plus de complexité, des dimensions plus importantes, plus de consommation d'énergie et des coûts plus élevés. Il n'est donc pas rare de rencontrer des processeurs 4-bit ou 8-bit dans des applications modernes, même si des processeurs 16-bit, 32-bit, 64-bit et même 128-bit sont disponibles. Pour bénéficier des avantages à la fois des tailles d'entier courtes et longues, beaucoup de processeurs sont conçus avec différentes largeurs d'entiers dans différentes parties du composant. Par exemple, le System/370 d'IBM est doté d'un processeur nativement 32-bit mais qui utilise une FPU de 128-bit de précision pour atteindre une plus grande précision dans les calculs avec les nombres flottants. Beaucoup des processeurs les plus récents utilisent une combinaison comparable de taille de nombres, spécialement lorsque le processeur est destiné à un usage généraliste pour lequel il est nécessaire de trouver le juste équilibre entre les capacités à traiter les nombres entiers et les nombres flottants.
Le signal d'horloge |
La plupart des processeurs, et plus largement la plupart des circuits de logique séquentielle, ont un fonctionnement synchrone par nature[note 3]. Cela veut dire qu'ils sont conçus et fonctionnent au rythme d'un signal de synchronisation. Ce signal est le « signal d'horloge ». Il prend souvent la forme d'une onde carrée périodique. En calculant le temps maximum que prend le signal électrique pour se propager dans les différentes branches des circuits du processeur, le concepteur peut sélectionner la période appropriée du signal d'horloge.
Cette période doit être supérieure au temps que prend le signal pour se propager dans le pire des cas. En fixant la période de l'horloge à une valeur bien au-dessus du pire des cas de temps de propagation, il est possible de concevoir entièrement le processeur et la façon dont il déplace les données autour des « fronts » montants ou descendants du signal d'horloge. Ceci a pour avantage de simplifier significativement le processeur tant du point de vue de sa conception que de celui du nombre de ses composants. Par contre, ceci a pour inconvénient le ralentissement du processeur puisque sa vitesse doit s'adapter à celle de son élément le plus lent, même si d'autres parties sont beaucoup plus rapides. Ces limitations sont largement compensées par différentes méthodes d'accroissement du parallélisme des processeurs (voir ci-dessous).
Les améliorations d'architecture ne peuvent pas, à elles seules, résoudre tous les inconvénients des processeurs globalement synchrones. Par exemple, un signal d'horloge est sujet à des retards comme tous les autres signaux électriques. Les fréquences d'horloge plus élevées que l'on trouve dans les processeurs à la complexité croissante engendrent des difficultés pour conserver le signal d'horloge en phase (synchronisé) à travers tout le processeur. En conséquence, beaucoup de processeurs actuels nécessitent plusieurs signaux d'horloge identiques de façon à éviter que le retard d'un seul signal ne puisse être la cause d'un dysfonctionnement du processeur. La forte quantité de chaleur qui doit être dissipée par le processeur constitue un autre problème majeur dû à l'accroissement des fréquences d'horloge. Les changements d'état fréquents de l'horloge font commuter un grand nombre de composants, qu'ils soient ou non utilisés à cet instant. En général, les composants qui commutent utilisent plus d'énergie que ceux qui restent dans un état statique. Ainsi, plus les fréquences d'horloge augmentent et plus la dissipation thermique en fait autant, ce qui fait que les processeurs requièrent des solutions de refroidissement plus efficaces.
La méthode de clock gating permet de gérer la commutation involontaire de composants en inhibant le signal d'horloge sur les éléments choisis mais cette pratique est difficile à implémenter et reste réservée aux besoins de circuits à très faible consommation.
Une autre méthode consiste à abandonner le signal global d'horloge ; la consommation d'énergie et la dissipation thermique sont réduites mais la conception du circuit devient plus complexe. On parle alors de processeurs asynchrones. Certaines conceptions ont été réalisés sans signal global d'horloge, utilisant par exemple les jeux d'instructions ARM ou MIPS, d'autres ne présentent que des parties asynchrones comme l'utilisation d'une UAL asynchrone avec un pipelining superscalaire pour atteindre des gains de performance dans les calculs arithmétiques. De tels processeurs sont actuellement plutôt réservés aux applications embarquées (ordinateurs de poche, consoles de jeux, etc.).
Parallélisme |
Modèle de processeur subscalaire : il faut 15 cycles d'horloge pour exécuter trois instructions.
La description du mode de fonctionnement de base d'un processeur présentée au chapitre précédent présente la forme la plus simple que peut prendre un processeur. Ce type de processeur, appelé subscalaire, exécute une instruction sur un ou deux flux de données à la fois.
Ce processus est inefficace et inhérent aux processeurs subscalaires. Puisqu'une seule instruction est exécutée à la fois, tout le processeur attend la fin du traitement de cette instruction avant de s'intéresser à la suivante avec pour conséquence que le processeur reste figé sur les instructions qui nécessitent plus d'un cycle d'horloge pour s'exécuter. L'ajout d'une seconde unité d'exécution (voir ci-dessous) ne permet pas d'améliorer notablement les performances, ce n'est plus une unité d'exécution qui se trouve figée mais deux, en augmentant encore le nombre de transistors inutilisés. Ce type de conception, dans laquelle les ressources d'exécution du processeur ne traitent qu'une seule instruction à la fois ne peut atteindre que des performances scalaires (une instruction par cycle d'horloge), voire subscalaires (moins d'une instruction par cycle d'horloge).
En tentant d'obtenir des performances scalaires et au-delà, on a abouti à diverses méthodes qui conduisent le processeur a un comportement moins linéaire et plus parallèle. Lorsqu'on parle de parallélisme de processeur, deux techniques de conception sont utilisées :
- parallélisme au niveau instruction (en anglais : instruction-level parallelism, ILP) ;
- parallélisme au niveau thread (en anglais : thread-level parallelism, TLP).
L'ILP vise à augmenter la vitesse à laquelle les instructions sont exécutées par un processeur (c’est-à-dire augmenter l'utilisation des ressources d'exécution présentes dans le circuit intégré).
Le TLP vise à augmenter le nombre de threads que le processeur pourra exécuter simultanément.
Chaque méthode diffère de l'autre d'une part, par la façon avec laquelle elle est implémentée et d'autre part, du fait de leur efficacité relative à augmenter les performances des processeurs pour une application.
ILP : pipelining et architecture superscalaire |

Pipeline de base à 5 étages. Dans le meilleur scénario, ce pipeline peut soutenir un taux d'exécution d'une instruction par cycle d'horloge.
Une des méthodes les plus simples pour accroître le parallélisme consiste à démarrer les premières étapes de recherche (fetch) et d'interprétation (decode) d'une instruction avant la fin de l'exécution de l'instruction précédente. C'est la forme la plus simple de la technique de pipelining. Elle est utilisée dans la plupart des processeurs modernes non spécialisés. Le pipelining permet d'exécuter plus d'une instruction à la fois en décomposant le cycle d'instruction en différentes étapes. Ce découpage peut être comparé à une chaîne d'assemblage.
Le pipelining peut créer des conflits de dépendance de données, lorsque le résultat de l'opération précédente est nécessaire à l'exécution de l'opération suivante. Pour résoudre ce problème, un soin particulier doit être apporté pour vérifier ce type de situation et retarder, le cas échéant, une partie du pipeline d'instruction. Naturellement, les compléments de circuits à apporter pour cela ajoutent à la complexité des processeurs parallèles. Un processeur parallèle peut devenir presque scalaire, ralenti uniquement par les attentes du pipeline (une instruction prend moins d'un cycle d'horloge par étape).
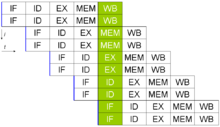
Pipeline superscalaire. En recherchant et affectant deux instructions à la fois, le processeur peut exécuter un maximum de deux instructions par cycle d'horloge.
Les développements suivants du pipelining ont conduit au développement d'une méthode qui diminue encore plus les temps d'attente des composants du processeur. Les architectures dites superscalaires comportent plusieurs unités d'exécution identiques[4]. Dans un processeur superscalaire, plusieurs instructions sont lues et transmises à un répartisseur qui décide si les instructions seront exécutées en parallèle (simultanément) ou non. Le cas échéant, les instructions sont réparties sur les unités d'exécution disponibles. En général, plus un processeur superscalaire est capable d'exécuter d'instructions en parallèle et plus le nombre d'instructions exécutées dans un cycle sera élevé.
La plupart des difficultés rencontrées dans la conception des architectures de processeurs superscalaires résident dans la mise au point du répartisseur. Le répartisseur doit être disponible rapidement et être capable de déterminer sans erreur si les instructions peuvent être exécutées en parallèle, il doit alors les distribuer de façon à charger les unités d'exécution autant qu'il est possible. Pour cela, le pipeline d'instructions doit être rempli aussi souvent que possible, créant le besoin d'une quantité importante de mémoire cache. Les techniques de traitement aléatoire comme la prédiction de branchement, l'exécution spéculative et la résolution des dépendances aux données deviennent cruciales pour maintenir un haut niveau de performance. En tentant de prédire quel branchement (ou chemin) une instruction conditionnelle prendra, le processeur peut minimiser le temps que tout le pipeline doit attendre jusqu'à la fin d'exécution de l'instruction conditionnelle. L'exécution spéculative améliore les performances modestes en exécutant des portions de code qui seront, ou ne seront pas, nécessaires à la suite d'une instruction conditionnelle. La résolution de la dépendance aux données est obtenue en réorganisant l'ordre dans lequel les instructions sont exécutées en optimisant la disponibilité des données.
Lorsque seule une partie de processeur est superscalaire, la partie qui ne l'est pas rencontre des problèmes de performance dus aux temps d'attente d'ordonnancement. Le Pentium original (P5) d'Intel disposait de deux ALU superscalaires qui pouvaient chacune accepter une instruction par cycle. Ensuite le P5 est devenu superscalaire pour les calculs sur les nombres entiers mais pas sur les nombres à virgule flottante. Les successeurs des architectures Pentium d'Intel, les P6, ont été dotés de capacités superscalaires pour les calculs sur les nombres à virgule flottante améliorant par là leurs performances en calcul flottant.
Les architectures à pipeline et superscalaires augmentent le parallélisme (ILP) des processeurs en permettant à un processeur unique d'exécuter des instructions à un rythme de plus d'une instruction par cycle. La plupart des processeurs d'aujourd'hui ont au moins une partie superscalaire. Au cours des dernières années, certaines évolutions dans la conception des processeurs à fort parallélisme ne se trouvent plus dans les circuits du processeur mais ont été placées dans le logiciel ou dans son interface avec le logiciel, le jeu d'instructions (instruction set architecture, ISA). La stratégie des instructions très longues (very long instruction word, VLIW) implémente certains parallélismes directement dans le logiciel, ce qui réduit la participation du processeur au gain de performance mais augmente aussi sa simplicité.
TLP : multithreading simultané et architecture multicœur |
Une autre stratégie communément employée pour augmenter le parallélisme des processeurs consiste à introduire la capacité d'exécuter plusieurs threads simultanément. De manière générale, les processeurs multithreads ont été utilisés depuis plus longtemps que les processeurs à pipeline. Bon nombre des conceptions pionnières, réalisées par la société Cray Research, datant de la fin des années 1970 et des années 1980, mettaient en œuvre principalement le TLP, dégageant alors de très grandes capacités de calcul (pour l'époque). En fait, le multithreading était connu dès les années 1950 (Smotherman 2005).
Dans le cas des processeurs simples, les deux méthodologies principales employées pour développer le TLP sont le multiprocessing au niveau circuit (chip-level multiprocessing, CMP) et le multithreading simultané (simultaneous multithreading, SMT). À un plus haut niveau, il est d'usage de réaliser des ordinateurs avec plusieurs processeurs totalement indépendants dans des organisations de type symétrique (symmetric multiprocessing, SMP), donc en particulier à accès mémoire uniforme (uniform memory access, UMA), ou asymétrique (asymmetric multiprocessing) à accès mémoire non uniforme (non uniform memory access, NUMA). Il s'agit alors de multiprocesseurs ou de processeurs multi-cœur. Alors que ces techniques diffèrent par les moyens qu'elles mettent en œuvre, elles visent toutes le même but : augmenter le nombre de threads qu'un processeur peut exécuter en parallèle.
Les méthodes de parallélisme CMP et SMP sont assez semblables et demandent plus d'effort de conception que l'utilisation de deux ou trois processeurs totalement indépendants. Dans le cas du CMP, plusieurs cœurs (cores) de processeurs sont intégrés dans le même boîtier, parfois même dans le même circuit intégré. Les SMP, eux, utilisent plusieurs boîtiers indépendants. Le NUMA est comparable au CMP mais met en œuvre un modèle d'accès mémoire non uniforme (les temps d'accès sont différents suivant que la mémoire est locale ou non locale à un processeur donné). Cette caractéristique est fondamentale dans les ordinateurs à plusieurs processeurs car pour les modèles SMP, la mémoire est partagée et les temps d'accès à la mémoire sont donc rapidement dégradés en cas d'accès simultané par plusieurs processeurs. À ce titre, le NUMA est considéré comme un modèle plus évolutif en nombre de processeurs.
SMT diffère des autres améliorations de TLP puisqu'il vise à dupliquer aussi peu de portions de processeur que possible. Sa mise en œuvre ressemble à une architecture superscalaire et se trouve souvent utilisée dans les microprocesseurs superscalaires (comme les POWER5 d'IBM). Plutôt que de dupliquer un processeur complet, la conception SMT ne duplique que les parties nécessaires pour la recherche (fetch), l'interprétation (decode) et la répartition des instructions (dispatch) ainsi que les registres non spécialisés. Ceci permet à un processeur SMT de maintenir ses unités d'exécution occupées plus souvent, en leur fournissant des instructions en provenance de deux threads différents. Comme on vient de la voir, le SMT est proche de l'architecture ILP superscalaire, mais cette dernière exécute des instructions en provenance du même thread.
Notes et références |
Notes |
Parce que l'architecture du jeu d'instruction d'un CPU est fondamentale pour son interface et utilisation, cela est souvent utilisé comme une classification pour le « type » de CPU. Par exemple, un CPU PowerPC utilise une variation du PowerPC ISA. Un système peut exécuter un ISA différent en exécutant un émulateur.
Parmi les premiers ordinateurs tel que le Harvard Mark I aucun type de sauts n'était supporté, limitant par conséquent la complexité des programmes pouvant être exécutés. C'est essentiellement pour cette raison que ces ordinateurs sont souvent considérés comme ne contenant pas un CPU propre, malgré leurs similitudes aux ordinateurs à programme enregistré.
Dans les faits, tous les CPU synchrones utilisent un mélange de logique séquentielle et de logique combinatoire (voir logique booléenne).
Références |
2,5 MHz pour le Zilog Z80 en 1976 / 4,77 MHz pour l'Intel 8088 sur le premier IBM-PC en 1981
4 GHz pour l'Intel Core i7 6700K en 2015
Liste des supercalculateurs les plus puissants du monde : http://top500.org/lists/2015/11/
(en) Jack Huynh, « The AMD Athlon XP Processor with 512KB L2 Cache », University of Illinois - Urbana-Champaign, 2003(consulté en septembre 2011), p. 6-11 [PDF]
Annexes |
.mw-parser-output .autres-projets ul{margin:0;padding:0}.mw-parser-output .autres-projets li{list-style-type:none;list-style-image:none;margin:0.2em 0;text-indent:0;padding-left:24px;min-height:20px;text-align:left}.mw-parser-output .autres-projets .titre{text-align:center;margin:0.2em 0}.mw-parser-output .autres-projets li a{font-style:italic}
Articles connexes |
- lithographie en immersion
- Microprocesseur
- Microcontrôleur
- Pipeline (informatique)
- Processeur graphique
- Processeur superscalaire
- Processeur synchrone
- Processeur asynchrone
- Processeur autosynchrone
- Processeur 64 bits
- Processeur vectoriel
- TPU
Liens externes |
 Portail de l’électricité et de l’électronique
Portail de l’électricité et de l’électronique  Portail de l’informatique
Portail de l’informatique  Portail des technologies
Portail des technologies


