Информационный поиск
Информацио́нный по́иск (англ. information retrieval) — процесс поиска неструктурированной документальной информации, удовлетворяющей информационные потребности[1], и наука об этом поиске.
Содержание
1 История
2 Информационный поиск как процесс
3 Виды поиска
4 Методы поиска
4.1 Адресный поиск
4.2 Семантический поиск
4.3 Документальный поиск
4.4 Фактографический поиск
5 Информационный поиск как наука
6 Запрос и объект запроса
7 Задачи информационного поиска
8 Оценки эффективности
8.1 Точность (precision)
8.2 Полнота (recall)
8.3 Выпадение (fall-out)
8.4 F-мера (F-measure, мера Ван Ризбергена)
9 См. также
10 Примечания
11 Литература
12 Ссылки
История |
Термин «информационный поиск» был впервые введён Кельвином Муэрсом в 1948 в его докторской диссертации, опубликован и употребляется в литературе с 1950.
Сначала системы автоматизированного ИП, или информационно-поисковые системы (ИПС), использовались лишь для поиска научной информации и литературы. Многие университеты и публичные библиотеки стали использовать ИПС для обеспечения доступа к книгам, журналам и другим документам. Широкое распространение ИПС получили с появлением сети Интернет и развитием Всемирной паутины. У русскоязычных пользователей наибольшей[2] популярностью пользуются поисковые системы Яндекс, Google.
Информационный поиск как процесс |
Поиск информации представляет собой процесс выявления в некотором множестве документов (текстов) всех тех, которые посвящены указанной теме (предмету), удовлетворяют заранее определенному условию поиска (запросу) или содержат необходимые (соответствующие информационной потребности) факты, сведения, данные.
Процесс поиска включает последовательность операций, направленных на сбор, обработку и предоставление информации.
В общем случае поиск информации состоит из четырех этапов:
- определение (уточнение) информационной потребности и формулировка информационного запроса;
- определение совокупности возможных держателей информационных массивов (источников);
- извлечение информации из выявленных информационных массивов;
- ознакомление с полученной информацией и оценка результатов поиска.
Виды поиска |
Полнотекстовый поиск — поиск по всему содержимому документа. Пример полнотекстового поиска — любой интернет-поисковик, например www.yandex.ru, www.google.com. Как правило, полнотекстовый поиск для ускорения поиска использует предварительно построенные индексы. Наиболее распространенной технологией для индексов полнотекстового поиска являются инвертированные индексы.
Поиск по метаданным — это поиск по неким атрибутам документа, поддерживаемым системой — название документа, дата создания, размер, автор и т. д. Пример поиска по реквизитам — диалог поиска в файловой системе (например, MS Windows).
Поиск изображений — поиск по содержанию изображения. Поисковая система распознает содержание фотографии (загружена пользователем или добавлен URL изображения). В результатах поиска пользователь получает похожие изображения. Так работают поисковые системы: Polar Rose, Picollator и др.
Методы поиска |
Адресный поиск |
Процесс поиска документов по чисто формальным признакам, указанным в запросе.
Для осуществления нужны следующие условия:
- Наличие у документа точного адреса
- Обеспечение строгого порядка расположения документов в запоминающем устройстве или в хранилище системы.
Адресами документов могут выступать адреса веб-серверов и веб-страниц и элементы библиографической записи, и адреса хранения документов в хранилище.
Семантический поиск |
Процесс поиска документов по их содержанию.
Условия:
- Перевод содержания документов и запросов с естественного языка на информационно-поисковый язык и составление поисковых образов документа и запроса.
- Составление поискового описания, в котором указывается дополнительное условие поиска.
Принципиальная разница между адресным и семантическим поисками состоит в том, что при адресном поиске документ рассматривается как объект с точки зрения формы, а при семантическом поиске — с точки зрения содержания.
При семантическом поиске находится множество документов без указания адресов.
В этом принципиальное отличие каталогов и картотек.
Библиотека — собрание библиографических записей без указания адресов.
Документальный поиск |
Процесс поиска в хранилище информационно-поисковой системы первичных документов или в базе данных вторичных документов, соответствующих запросу пользователя.
Два вида документального поиска:
- Библиотечный, направленный на нахождение первичных документов.
- Библиографический, направленный на нахождение сведений о документах, представленных в виде библиографических записей.
Фактографический поиск |
Процесс поиска фактов, соответствующих информационному запросу.
К фактографическим данным относятся сведения, извлеченные из документов, как первичных, так и вторичных и получаемые непосредственно из источников их возникновения.
Различают два вида:
- Документально-фактографический, заключается в поиске в документах фрагментов текста, содержащих факты.
- Фактологический (описание фактов), предполагающий создание новых фактографических описаний в процессе поиска путём логической переработки найденной фактографической информации.
Информационный поиск как наука |
Информационный поиск — большая междисциплинарная область науки, стоящая на пересечении когнитивной психологии, информатики, информационного дизайна, лингвистики, семиотики, и библиотечного дела.
Поиск информации — процесс выявления в массиве информации записей, удовлетворяющих заранее определенному условию поиска или запросу.
ИП рассматривает поиск информации в документах, поиск самих документов, извлечение метаданных из документов, поиск текста, изображений, видео и звука в локальных реляционных базах данных, в гипертекстовых базах данных таких, как Интернет и локальные интранет-системы.
Существует некоторая путаница, связанная с понятиями поиска данных, поиска документов, информационного поиска и текстового поиска. Тем не менее, каждое из этих направлений исследования обладает собственными методиками, практическими наработками и литературой.
В настоящее время ИП — это бурно развивающаяся область науки, популярность которой обусловлена экспоненциальным ростом объемов информации, в частности в сети Интернет. ИП посвящена обширная литература и множество конференций. Одной из наиболее известных является TREC, организованной в 1992 Министерством обороны США совместно с Институтом Стандартов и Технологий (NIST) с целью консолидации исследовательского сообщества и развития методик оценки качества ИП.
Запрос и объект запроса |
Говоря о системах ИП, употребляют термины запрос и объект запроса.
Запрос — это формализованный способ выражения информационных потребностей пользователем системы. Для выражения информационной потребности используется язык поисковых запросов, синтаксис варьируется от системы к системе. Кроме специального языка запросов, современные поисковые системы позволяют вводить запрос на естественном языке.
Объект запроса — это информационная сущность, которая хранится в базе автоматизированной системы поиска. Несмотря на то, что наиболее распространенным объектом запроса является текстовый документ, не существует никаких принципиальных ограничений. В частности, возможен поиск изображений, музыки и другой мультимедиа информации. Процесс занесения объектов поиска в ИПС называется индексацией. Далеко не всегда ИПС хранит точную копию объекта, нередко вместо неё хранится суррогат.
Задачи информационного поиска |
Центральная задача ИП — помочь пользователю удовлетворить его информационную потребность. Так как описать информационные потребности пользователя технически непросто, они формулируются как некоторый запрос, представляющий из себя набор ключевых слов, характеризующий то, что ищет пользователь.
Классическая задача ИП, с которой началось развитие этой области, — это поиск документов, удовлетворяющих запросу, в рамках некоторой статической коллекции документов. Но список задач ИП постоянно расширяется и теперь включает:
- Вопросы моделирования;
Классификация документов;
Фильтрация документов;
Кластеризация документов;
Проектирование архитектур поисковых систем и пользовательских интерфейсов;- Извлечение информации, в частности аннотирования и реферирования документов;
Языки запросов и др.
Также, перед движками ИП ставятся некоторые задачи по обработке естественных языков, что включает в себя морфологический анализ, разрешение лексической многозначности и так далее.
Оценки эффективности |
Существует много способов оценить насколько хорошо документы, найденные ИПС, соответствуют запросу. К сожалению, понятие степени соответствия запроса, или другими словами релевантности, является субъективным понятием, а степень соответствия зависит от конкретного человека, оценивающего результаты выполнения запроса.
Точность (precision) |
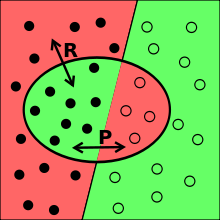
На этом рисунке релевантные точки (rel) находятся слева от прямой, а точки, найденные поисковой системой (retr), находятся в овале. Области красного цвета представляют ошибки поисковой системы. Красная область слева — это релевантные точки, не найденные системой (пропуск события), красная область справа — найденные, но нерелевантные точки (ложная тревога). Точность — это пропорция левой зелёной области по отношению к овалу (горизонтальная стрелка). Полнота — это пропорция левой зелёной области к области слева от прямой (диагональная стрелка).
Определяется как отношение числа релевантных документов, найденных ИПС, к общему числу найденных документов:
Precision=|Drel∩ Dretr||Dretr|{displaystyle {mbox{Precision}}={frac {|D_{rel}cap D_{retr}|}{|D_{retr}|}}},
где Drel{displaystyle D_{rel}}

Полнота (recall) |
Отношение числа найденных релевантных документов, к общему числу релевантных документов в базе:
Recall=|Drel∩ Dretr||Drel|{displaystyle {mbox{Recall}}={frac {|D_{rel}cap D_{retr}|}{|D_{rel}|}}},
где Drel{displaystyle D_{rel}}
Выпадение (fall-out) |
Выпадение характеризует вероятность нахождения нерелевантного ресурса и определяется, как отношение числа найденных нерелевантных документов к общему числу нерелевантных документов в базе:
Fall-out=|Dnrel∩ Dretr||Dnrel|{displaystyle {mbox{Fall-out}}={frac {|D_{nrel}cap D_{retr}|}{|D_{nrel}|}}},
где Dnrel{displaystyle D_{nrel}}
F-мера (F-measure, мера Ван Ризбергена) |
Иногда бывает полезно объединить точность и полноту в одной усреднённой величине. Для этой цели среднее арифметическое не подходит, так как, например, поисковой системе достаточно вернуть вообще все документы, чтобы обеспечить равную единице полноту при близкой к нулю точности, и среднее арифметическое точности и полноты будет не меньше 1/2. Среднее гармоническое не обладает этим недостатком, поскольку при большом отличии усредняемых значений приближается к минимальному из них.
Поэтому хорошей мерой для совместной оценки точности и полноты является F-мера, которая определяется как взвешенное гармоническое среднее точности P и полноты R:
- F=1α1P+(1−α)1R,α∈[0,1].{displaystyle F={frac {1}{alpha {frac {1}{P}}+(1-alpha ){frac {1}{R}}}},qquad alpha in [0,1].}
![F={frac {1}{alpha {frac {1}{P}}+(1-alpha ){frac {1}{R}}}},qquad alpha in [0,1].](https://wikimedia.org/api/rest_v1/media/math/render/svg/9efd466d9c9cd3549100d5a04f22a6b7553e77ed)
Обычно F-меру записывают в виде
- F=(β2+1)PRβ2P+R,β2=(1−α)α,β2∈[0,∞].{displaystyle F={frac {(beta ^{2}+1)PR}{beta ^{2}P+R}},qquad beta ^{2}={frac {(1-alpha )}{alpha }},quad beta ^{2}in [0,infty ].}
![F={frac {(beta ^{2}+1)PR}{beta ^{2}P+R}},qquad beta ^{2}={frac {(1-alpha )}{alpha }},quad beta ^{2}in [0,infty ].](https://wikimedia.org/api/rest_v1/media/math/render/svg/e1c5eb19a23e6d9df710d69e402cb66703ceda79)
При α=1/2{displaystyle alpha =1/2}



- F1=2PRP+R.{displaystyle F_{1}={frac {2PR}{P+R}}.}

Использование сбалансированной F-меры не является обязательным: при 0<β<1{displaystyle 0<beta <1}

См. также |
- Электронные библиотеки
- Полнотекстовый поиск
- Поисковые системы
Российский семинар по оценке методов информационного поиска (РОМИП)
Примечания |
↑ Manning et al, 2011, pp. 23.
↑ Переходы — ANALYZETHIS.RU
Литература |
- Baeza-Yates R., Ribeiro-Neto B. Modern Information Retrieval. — Addison-Wesley, 1999. — ISBN 0-201-39829-X.
Manning C., Raghavan P., Schütze H. Introduction to Information Retrieval. — Cambridge University Press, 2008. — ISBN 0-521-86571-9.
- Перевод: Маннинг К., Рагхаван П., Шютце Х. Введение в информационный поиск. — Вильямс, 2011. — ISBN 978-5-8459-1623-5.
- Перевод: Маннинг К., Рагхаван П., Шютце Х. Введение в информационный поиск. — Вильямс, 2011. — ISBN 978-5-8459-1623-5.
- Ландэ Д. В., Снарский А. А., Безсуднов И. В. Интернетика: Навигация в сложных сетях: модели и алгоритмы. — M.: Либроком (Editorial URSS), 2009. — 264 с. — ISBN 978-5-397-00497-8.
Ссылки |
 ru_ir — сообщество «Информационный поиск» в «Живом Журнале»
ru_ir — сообщество «Информационный поиск» в «Живом Журнале»
Юрий Лифшиц. Курс лекций «Алгоритмы для Интернета»
Кураленок И. Е., Некрестьянов И. С. Обзор «Оценка систем текстового поиска»


