Ácido ribonucleico

ARN mensajero.
El ácido ribonucleico (ARN o RNA) es un ácido nucleico formado por una cadena de ribonucleótidos. Está presente tanto en las células procariotas como en los eucariotas, y es el único material genético de ciertos virus (virus ARN).
El ARN se puede definir como la molécula formada por una cadena simple de ribonucleótidos, cada uno de ellos formado por ribosa, un fosfato y una de las cuatro bases nitrogenadas (adenina, guanina, citosina y uracilo). El ARN celular es lineal y monocatenario (de una sola cadena), pero en el genoma de algunos virus es de doble hebra.[1]
En los organismos celulares desempeña diversas funciones. Es la molécula que dirige las etapas intermedias de la síntesis proteica; el ADN no puede actuar solo, y se vale del ARN para transferir esta información vital durante la síntesis de proteínas (producción de las proteínas que necesita la célula para sus actividades y su desarrollo). Varios tipos de ARN regulan la expresión génica, mientras que otros tienen actividad catalítica. El ARN es, pues, mucho más versátil que el ADN.
Índice
1 Descubrimiento e historia
2 Bioquímica del ARN
2.1 Apareamiento doble
3 Estructura
3.1 Estructura primaria
3.2 Estructura secundaria
3.3 Estructura terciaria
3.3.1 Hélice A
4 Biosíntesis
5 Clases de ARN
5.1 ARN implicados en la síntesis de proteínas
5.1.1 ARN mensajero (ARNm)
5.1.2 ARN de transferencia (ARNt)
5.1.3 ARN ribosómico o ribosomal (ARNr)
5.2 ARN reguladores
5.2.1 ARN de interferencia
5.2.2 Micro ARN
5.2.3 ARN interferente pequeño
5.2.4 ARN asociados a Piwi
5.2.5 ARN antisentido
5.2.6 ARN largo no codificante
5.2.7 Riboswitch
5.3 ARN con actividad catalítica
5.3.1 Ribozimas
5.3.2 Espliceosoma
5.3.3 ARN pequeño nucleolar
6 ARN mitocondrial
7 Genomas de ARN
8 Hipótesis del mundo de ARN
9 Véase también
10 Referencias
11 Enlaces externos
Descubrimiento e historia
Los ácidos nucleicos fueron descubiertos en 1867 por Friedrich Miescher, que los llamó nucleína ya que los aisló del núcleo celular.[2] Más tarde, se comprobó que las células procariotas, que carecen de núcleo, también contenían ácidos nucleicos. El papel del ARN en la síntesis de proteínas fue sospechado en 1939.[3] Severo Ochoa ganó el Premio Nobel de Medicina en 1959 tras descubrir cómo se sintetizaba el ARN.[4]
En 1965 Robert W. Holley halló la secuencia de 77 nucleótidos de un ARN de transferencia de una levadura,[5] con lo que obtuvo el Premio Nobel de Medicina en 1968. En 1967, Carl Woese comprobó las propiedades catalíticas de algunos ARN y sugirió que las primeras formas de vida usaron ARN como portador de la información genética tanto como catalizador de sus reacciones metabólicas (hipótesis del mundo de ARN).[6][7] En 1976, Walter Fiers y sus colaboradores determinaron la secuencia completa del ARN del genoma de un virus ARN (bacteriófago MS2).[8]
En 1990 se descubrió en Petunia que genes introducidos pueden silenciar genes similares de la misma planta, lo que condujo al descubrimiento del ARN interferente.[9][10] Aproximadamente al mismo tiempo se hallaron los micro ARN, pequeñas moléculas de 22 nucleótidos que tenían algún papel en el desarrollo de Caenorhabditis elegans.[11] El descubrimiento de ARN que regulan la expresión génica ha permitido el desarrollo de medicamentos hechos de ARN, como los ARN pequeños de interferencia que silencian genes.[12]
En el año 2016 se tiene prácticamente por comprobado que las moléculas de ARN fueron la primera forma de vida propiamente dicha en habitar el planeta Tierra (Hipótesis del mundo de ARN).
Bioquímica del ARN

Estructura química del RNA.

Comparativa entre ARN y ADN.
Como el ADN, el ARN está formado por una cadena de monómeros repetitivos llamados nucleótidos. Los nucleótidos se unen uno tras otro mediante enlaces fosfodiéster cargados negativamente.
Cada nucleótido está formado por tres componentes:
- Un monosacárido de cinco carbonos (pentosa) llamada ribosa
- Un grupo fosfato
- Una base nitrogenada, que puede ser
- Adenina (A)
- Citosina (C)
- Guanina (G)
- Uracilo (U)
| ARN | ADN | |
|---|---|---|
| Pentosa | Ribosa | Desoxirribosa |
| Purinas | Adenina y Guanina | Adenina y Guanina |
| Pirimidinas | Citosina y Uracilo | Citosina y Timina |
Los carbonos de la ribosa se numeran de 1' a 5' en sentido horario. La base nitrogenada se une al carbono 1'; el grupo fosfato se une al carbono 5' y al carbono 3' de la ribosa del siguiente nucleótido. El pico tiene una carga negativa a pH fisiológico lo que confiere al ARN carácter polianiónico. Las bases púricas (adenina y guanina) pueden formar puentes de hidrógeno con las pirimidínicas (uracilo y citosina) según el esquema C=G y A=U.[13] Además, son posibles otras interacciones, como el apilamiento de bases[14] o tetrabucles con apareamientos G=A.[13]
Muchos ARN contienen además de los nucleótidos habituales, nucleótidos modificados, que se originan por transformación de los nucleótidos típicos; son característicos de los ARN de transferencia (ARNt) y el ARN ribosómico (ARNr); también se encuentran nucleótidos metilados en el ARN mensajero eucariótico.[15]
Apareamiento doble

Apareamiento entre guanina y uracilo
La interacción por puentes de hidrógeno descrita por Watson y Crick[16] forma pares de bases entre una purina y una pirimidina. A este patrón se le conoce como apareamiento Watson y Crick. En éste, la adenina se aparea con el uracilo (timina, en ADN) y la citosina con la guanina. Sin embargo en el ARN se presentan muchas otras formas de apareamiento, de las cuales la más ubicua es el apareamiento wobble (también apareamiento por balanceo o apareamiento titubeante) para la pareja G-U. Éste fue propuesto por primera vez por Crick para explicar el apareamiento codón-anticodón en los tRNAs y ha sido confirmado en casi todas las clases de RNA en los tres dominios filogenéticos.[17]
Estructura
Estructura primaria
Se refiere a la secuencia lineal de nucleótidos en la molécula de ARN. Los siguientes niveles estructurales (estructura secundaria, terciaria) son consecuencia de la estructura primaria. Además, la secuencia misma puede ser información funcional; ésta puede traducirse para sintetizar proteínas (en el caso del mRNA) o funcionar como región de reconocimiento, región catalítica, entre otras.
Estructura primaria de tRNAPhe
Estructura secundaria

Estructura secundaria de ARN de transferencia: tRNAPhe de S. cerevisiae.
El ARN se pliega como resultado de la presencia de regiones cortas con apareamiento intramolecular de bases, es decir, pares de bases formados por secuencias complementarias más o menos distantes dentro de la misma hebra. La estructura secundaria se refiere, entonces, a las relaciones de apareamiento de bases: «El término ‘estructura secundaria’ denota cualquier patrón plano de contactos por apareamiento de bases. Es un concepto topológico y no debe ser confundido con algún tipo de estructura bidimensional».[18] La estructura secundaria puede ser descrita a partir de motivos estructurales que se suelen clasificar de la siguiente manera:
| Hélice (tallo, stack) | Región con bases apareadas | |
|---|---|---|
| Bucle (ciclo, loop) | Región incluida en una hélice en donde las bases no están apareadas | 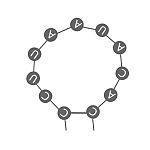 |
| Bucle en horquilla (tallo y bucle, hairpin loop) | Estructura en donde regiones cercanas de bases complementarias se aparean, separadas por una región no apareada que permite que la secuencia se doble para formar una hélice. | 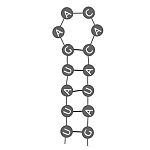 |
| Bucle interno (internal loop) | Estructura en donde hay regiones no apareadas en ambos lados de la hebra. Puede ser simétrico o asimétrico. | 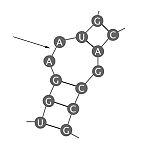 |
| Protuberancia (buldge) | Estructura en donde hay una región no apareada en un solo lado de la hebra. | 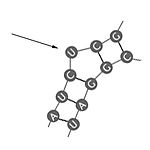 |
| Bucle múltiple (helical junction) | Región en donde se juntan múltiples hélices. | 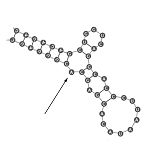 |
| Pseudonudo | Variación de bucle en donde sólo una parte del bucle sí está apareada. El pseudonudo más simple consiste de una región libre del RNA apareada con un bucle. | 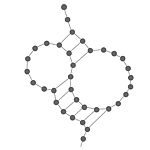 |
Estructura terciaria

Estructura terciaria de dos ARN de transferencia: tRNAPhe y tRNAAsx
La estructura terciaria es el resultado de las interacciones en el espacio entre los átomos que conforman la molécula. Algunas interacciones de este tipo incluyen el apilamiento de bases y los apareamientos de bases distintos a los propuestos por Watson y Crick, como el apareamiento Hoogsteen, los apareamientos triples y los zippers de ribosa.
Hélice A

Hélice A de RNA
A diferencia del ADN las moléculas de ARN suelen ser de cadena simple y no forman dobles hélices extensas, no obstante, en las regiones con bases apareadas sí forma hélices como motivo estructural terciario. Una importante característica estructural del ARN que lo distingue del ADN es la presencia de un grupo hidroxil en posición 2' de la ribosa, que causa que las dobles hélices de ARN adopten una conformación A, en vez de la conformación B que es la más común en el ADN.[20] Esta hélice A tiene un surco mayor muy profundo y estrecho y un surco menor amplio y superficial.[21] Una segunda consecuencia de la presencia de dicho hidroxilo es que los enlaces fosfodiéster del ARN de las regiones en que no se forma doble hélice son más susceptibles de hidrólisis química que los del ADN; los enlaces fosfodiéster del ARN se hidrolizan rápidamente en disolución alcalina, mientras que los enlaces del ADN son estables.[22] La vida media de las moléculas de ARN es mucho más corta que las del ADN, de unos minutos en algunos ARN bacterianos o de unos días en los ARNt humanos.[15]
Biosíntesis
La biosíntesis de ARN está catalizada normalmente por la enzima ARN polimerasa que usa una hebra de ADN como molde, proceso conocido con el nombre de transcripción. Por tanto, todos los ARN celulares provienen de copias de genes presentes en el ADN.
La transcripción comienza con el reconocimiento por parte de la enzima de un promotor, una secuencia característica de nucleótidos en el ADN situada antes del segmento que va a transcribirse; la doble hélice del ADN es abierta por la actividad helicasa de la propia enzima. A continuación, la ARN polimerasa progresa a lo largo de la hebra de ADN en sentido 3' → 5', sintetizando una molécula complementaria de ARN; este proceso se conoce como elongación, y el crecimiento de la molécula de ARN se produce en sentido 5' → 3'. La secuencia de nucleótidos del ADN determina también dónde acaba la síntesis del ARN, gracias a que posee secuencias características que la ARN polimerasa reconoce como señales de terminación.[23]
Tras la transcripción, la mayoría de los ARN son modificados por enzimas. Por ejemplo, al pre-ARN mensajero eucariota recién transcrito se le añade un nucleótido de guanina modificado (7-Metilguanosina) en el extremo 5' por medio de un puente de trifosfato formando un enlace 5'→ 5' único, también conocido como "capucha" o "caperuza", y una larga secuencia de nucleótidos de adenina en el extremo 3' (cola poli-A); posteriormente se le eliminan los intrones (segmentos no codificantes) en un proceso conocido como splicing.
En virus, hay también varias ARN polimerasas ARN-dependientes que usan ARN como molde para la síntesis de nuevas moléculas de ARN. Por ejemplo, varios virus ARN, como los poliovirus, usan este tipo de enzimas para replicar su genoma.[24][25]
Clases de ARN
El ARN mensajero (ARNm) es el tipo de ARN que lleva la información del ADN a los ribosomas, el lugar de la síntesis de proteínas. La secuencia de nucleótidos del ARNm determina la secuencia de aminoácidos de la proteína.[26] Por ello, el ARNm es denominado ARN codificante.
No obstante, muchos ARN no codifican proteínas, y reciben el nombre de ARN no codificantes; se originan a partir de genes propios (genes ARN), o son los intrones rechazados durante el proceso de splicing. Son ARN no codificantes el ARN de transferencia (ARNt) y el ARN ribosómico (ARNr), que son elementos fundamentales en el proceso de traducción, y diversos tipos de ARN reguladores.[27]
Ciertos ARN no codificantes, denominados ribozimas, son capaces de catalizar reacciones químicas como cortar y unir otras moléculas de ARN,[28] o formar enlaces peptídicos entre aminoácidos en el ribosoma durante la síntesis de proteínas.[29]
ARN implicados en la síntesis de proteínas

Ribosoma 50S mostrando el ARNr (amarillo), las proteínas (azul) y el centro activo, la adenina 2486 (rojo).
ARN mensajero (ARNm)
El ARN mensajero (ARNm o RNAm) lleva la información sobre la secuencia de aminoácidos de la proteína desde el ADN, lugar en que está inscrita, hasta el ribosoma, lugar en que se sintetizan las proteínas de la célula. Es, por tanto, una molécula intermediaria entre el ADN y la proteína y apelativo de "mensajero" es del todo descriptivo. En eucariotas, el ARNm se sintetiza en el nucleoplasma del núcleo celular y donde es procesado antes de acceder al citosol, donde se hallan los ribosomas, a través de los poros de la envoltura nuclear.
ARN de transferencia (ARNt)
Los ARN de transferencia (ARNt o tRNA) son cortos polímeros de unos 80 nucleótidos que transfiere un aminoácido específico al polipéptido en crecimiento; se unen a lugares específicos del ribosoma durante la traducción. Tienen un sitio específico para la fijación del aminoácido (extremo 3') y un anticodón formado por un triplete de nucleótidos que se une al codón complementario del ARNm mediante puentes de hidrógeno.[27] Estos ARNt, al igual que otros tipos de ARN, pueden ser modificados post-transcripcionalmente por enzimas. La modificación de alguna de sus bases es crucial para la descodificación de ARNm y para mantener la estructura tridimensional del ARNt.[30]
ARN ribosómico o ribosomal (ARNr)
El ARN ribosómico o ribosomal (ARNr o RNAr) se halla combinado con proteínas para formar los ribosomas, donde representa unas 2/3 partes de los mismos. En procariotas, la subunidad mayor del ribosoma contiene dos moléculas de ARNr y la subunidad menor, una. En los eucariotas, la subunidad mayor contiene tres moléculas de ARNr y la menor, una. En ambos casos, sobre el armazón constituido por los ARNm se asocian proteínas específicas. El ARNr es muy abundante y representa el 80 % del ARN hallado en el citoplasma de las células eucariotas.[31] Los ARN ribosómicos son el componente catalítico de los ribosomas; se encargan de crear los enlaces peptídicos entre los aminoácidos del polipéptido en formación durante la síntesis de proteínas; actúan, pues, como ribozimas.
ARN reguladores
Muchos tipos de ARN regulan la expresión génica gracias a que son complementarios de regiones específicas del ARNm o de genes del ADN.
ARN de interferencia
Los ARN interferentes (ARNi o iRNA) son moléculas de ARN que suprimen la expresión de genes específicos mediante mecanismos conocidos globalmente como ribointerferencia o interferencia por ARN. Los ARN interferentes son moléculas pequeñas (de 20 a 25 nucléotidos) que se generan por fragmentación de precursores más largos. Se pueden clasificar en tres grandes grupos:[32]
Micro ARN
Los micro ARN (miARN o RNAmi) son cadenas cortas de 21 o 22 nucleótidos hallados en células eucariotas que se generan a partir de precursores específicos codificados en el genoma. Al transcribirse, se pliegan en horquillas intramoleculares y luego se unen a enzimas formando un complejo efector que puede bloquear la traducción del ARNm o acelerar su degradación comenzando por la eliminación enzimática de la cola poli A.[33][34]
ARN interferente pequeño
Los ARN interferentes pequeños (ARNip o siARN), formados por 20-25 nucleótidos, se producen con frecuencia por rotura de ARN virales, pero pueden ser también de origen endógeno.[35][36] Tras la transcripción se ensambla en un complejo proteico denominado RISC (RNA-induced silencing complex) que identifica el ARNm complementario que es cortado en dos mitades que son degradadas por la maquinaria celular, bloquean así la expresión del gen.[37][38][39]
ARN asociados a Piwi
Los ARN asociados a Piwi[40] son cadenas de 29-30 nucleótidos, propias de animales; se generan a partir de precursores largos monocatenarios (formados por una sola cadena), en un proceso que es independiente de Drosha y Dicer. Estos ARN pequeños se asocian con una subfamilia de las proteínas "Argonauta" denominada proteínas Piwi. Son activos las células de la línea germinal; se cree que son un sistema defensivo contra los transposones y que juegan algún papel en la gametogénesis.[41][42]
ARN antisentido
Un ARN antisentido es la hebra complementaria (no codificadora) de un hebra ARNm (codificadora). La mayoría inhiben genes, pero unos pocos activan la transcripción.[43] El ARN antisentido se aparea con su ARNm complementario formando una molécula de doble hebra que no puede traducirse y es degradada enzimáticamente.[44] La introducción de un transgen codificante para un ARNm antisentido es una técnica usada para bloquear la expresión de un gen de interés. Un mARN antisentido marcado radioactivamente puede usarse para mostrar el nivel de transcripción de genes en varios tipos de células. Algunos tipos estructurales antisentidos son experimentales, ya que se usan como terapia antisentido.
ARN largo no codificante
Muchos ARN largos no codificantes (ARNnc largo o long ncARN) regulan la expresión génica en eucariotas;[45] uno de ellos es el Xist que recubre uno de los dos cromosomas X en las hembras de los mamíferos inactivándolo (corpúsculo de Barr).[46]
Diversos estudios revelan que es activo a bajos niveles. En determinadas poblaciones celulares, una cuarta parte de los genes que codifican para proteínas y el 80 % de los lncRNA detectados en el genoma humano están presentes en una o ninguna copia por célula, ya que existe una restricción en determinados ARN.[47]
Riboswitch
Un riboswitch es una parte del ARNm (ácido ribonucleico mensajero) al cual pueden unirse pequeñas moléculas que afectan la actividad del gen.[48][49][50] Por tanto, un ARNm que contenga un riboswitch está directamente implicado en la regulación de su propia actividad que depende de la presencia o ausencia de la molécula señalizadora. Tales riboswitchs se hallan en la región no traducida 5' (5'-UTR), situada antes del codón de inicio (AUG), y/o en la región no traducida 3' (3'-UTR), también llamada secuencia de arrastre,[15] situada entre el codón de terminación (UAG, UAA o UGA) y la cola poli A.[50]
ARN con actividad catalítica

Transformación de uridina en pseudouridina, una modificación común del ARN.
Ribozimas
El ARN puede actuar como biocatalizador. Ciertos ARN se asocian a proteínas formando ribonucleoproteínas y se ha comprobado que es la subunidad de ARN la que lleva a cabo las reacciones catalíticas; estos ARN realizan las reacciones in vitro en ausencia de proteína. Se conocen cinco tipos de ribozimas; tres de ellos llevan a cabo reacciones de automodificación, como eliminación de intrones o autocorte, mientras que los otros (ribonucleasa P y ARN ribosómico) actúan sobre substratos distintos.[15] Así, la ribonucleasa P corta un ARN precursor en moléculas de ARNt,[51] mientras que el ARN ribosómico realiza el enlace peptídico durante la síntesis proteica ribosomal.
Espliceosoma
Los intrones son separados del pre-ARNm durante el proceso conocido como splicing por los espliceosomas, que contienen numerosos ARN pequeños nucleares (ARNpn o snRNA).[52] En otros casos, los propios intrones actúan como ribozimas y se separan a sí mismos de los exones.[53]
ARN pequeño nucleolar
Los ARN pequeños nucleolares (ARNpno o snoRNA), hallados en el nucléolo y en los cuerpos de Cajal, dirigen la modificación de nucleótidos de otros ARN;[27] el proceso consiste en transformar alguna de las cuatro bases nitrogenadas típicas (A, C, U, G) en otras. Los ARNpno se asocian con enzimas y los guían apareándose con secuencias específicas del ARN al que modificarán. Los ARNr y los ARNt contienen muchos nucleótidos modificados.[54][55]
ARN mitocondrial
La mitocondrias tienen su propio aparato de síntesis proteica, que incluye ARNr (en los ribosomas), ARNt y ARNm.
Los ARN mitocondriales (ARNmt o mtARN) representan el 4 % del ARN celular total. Son transcritos por una ARN polimerasa mitocondrial específica.[15]
Genomas de ARN
El ADN es la molécula portadora de la información genética en todos los organismos celulares, pero, al igual que el ADN, el ARN puede guardar información genética. Los virus ARN carecen por completo de ADN y su genoma está formado por ARN, el cual codifica las proteínas del virus, como las de la cápside y algunos enzimas. Dichos enzimas realizan la replicación del genoma vírico. Los viroides son otro tipo de patógenos que consisten exclusivamente en una molécula de ARN que no codifica ninguna proteína y que es replicado por la maquinaria de la célula hospedadora.[56]
Hipótesis del mundo de ARN
La hipótesis del mundo de ARN propone que el ARN fue la primera forma de vida en la Tierra, desarrollando posteriormente una membrana celular a su alrededor y convirtiéndose así en la primera célula. Se basa en la comprobación de que el ARN puede contener información genética, de un modo análogo a como lo hace el ADN, y que algunos tipos son capaces de llevar a cabo reacciones metabólicas, como autocorte o formación de enlaces peptídicos.
Durante años se especuló en qué fue primero, el ADN o las enzimas, ya que las enzimas se sintetizan a partir del ADN y la síntesis de ADN es llevada a cabo por enzimas. Si se supone que las primeras formas de vida usaron el ARN tanto para almacenar su información genética como realizar su metabolismo, se supera este escollo. Experimentos con los ribozimas básicos, como el ARN viral Q-beta, han demostrado que las estructuras de ARN autorreplicantes sencillas pueden resistir incluso a fuertes presiones selectivas (como los terminadores de cadena de quiralidad opuesta).[57]
Véase también
- ARN nucleolar
- Hipótesis del mundo de ARN
Referencias
↑ Bioquímica: libro de texto con aplicaciones clínicas, pág. 78. En Google Libros.
↑ Dahm, R. (2005). «Friedrich Miescher and the discovery of DNA». Developmental Biology 278 (2): 274-88. PMID 15680349. doi:10.1016/j.ydbio.2004.11.028.
↑ Caspersson, T., Schultz, J. (1939). «Pentose nucleotides in the cytoplasm of growing tissues». Nature 143: 602-3. doi:10.1038/143602c0.
↑ Ochoa, S. (1959). «Enzymatic synthesis of ribonucleic acid». Nobel Lecture.
↑ Holley, R. W. et al (1965). «Structure of a ribonucleic acid». Science 147 (1664): 1462-65. PMID 14263761. doi:10.1126/science.147.3664.1462.
↑ Siebert, S. (2006). «Common sequence structure properties and stable regions in RNA secondary structures». Dissertation, Albert-Ludwigs-Universität, Freiburg im Breisgau. p. 1. Archivado desde el original el 9 de marzo de 2012.
↑ Szathmáry, E. (1999). «The origin of the genetic code: amino acids as cofactors in an RNA world». Trends Genet. 15 (6): 223-9. PMID 10354582. doi:10.1016/S0168-9525(99)01730-8.
↑ Fiers, W. et al (1976). «Complete nucleotide-sequence of bacteriophage MS2-RNA: primary and secondary structure of replicase gene». Nature 260: 500-7. PMID 1264203. doi:10.1038/260500a0.
↑ Napoli, C., Lemieux, C. & Jorgensen, R. (1990). «Introduction of a chimeric chalcone synthase gene into petunia results in reversible co-suppression of homologous genes in trans». Plant Cell 2 (4): 279-89. PMID 12354959. doi:10.1105/tpc.2.4.279.
↑ Dafny-Yelin, M., Chung, S.M., Frankman, E. L. & Tzfira, T. (diciembre de 2007). «pSAT RNA interference vectors: a modular series for multiple gene down-regulation in plants». Plant Physiol. 145 (4): 1272-81. PMC 2151715. PMID 17766396. doi:10.1104/pp.107.106062.
↑ Ruvkun, G. (2001). «Glimpses of a tiny RNA world». Science 294 (5543): 797-99. PMID 11679654. doi:10.1126/science.1066315.
↑ Fichou, Y. & Férec, C. (2006). «The potential of oligonucleotides for therapeutic applications». Trends in Biotechnology 24 (12): 563-70. PMID 17045686. doi:10.1016/j.tibtech.2006.10.003.
↑ ab Lee, J. C. & Gutell, R. R. (2004). «Diversity of base-pair conformations and their occurrence in rRNA structure and RNA structural motifs». J. Mol. Biol. 344 (5): 1225-49. PMID 15561141. doi:10.1016/j.jmb.2004.09.072.
↑ Barciszewski, J., Frederic, B. & Clark, C. (1999). RNA biochemistry and biotechnology. Springer. pp. 73-87. ISBN 0792358627. OCLC 52403776.
↑ abcde Devlin, T. M. 2004. Bioquímica, 4.ª edición. Reverté, Barcelona. ISBN 84-291-7208-4
↑ Watson, J. D., & Crick, F. H. (1953). «Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acid». Nature 171: 737-738.
↑ Brown, T. (2004). Genomas. Ed. Médica Paanamericana.
↑ Fontana, W. (2002). «Modelling “evo-devo” with RNA». BioEssays: News and Reviews in Molecular, Cellular and Developmental Biology 24 (12): 1164-77. doi:10.1002/bies.10190.
↑ Tabla recopilada en Quinones Olvera, N. Implicaciones evolutivas de la plasticidad del RNA. (Tesis) Universidad Nacional Autónoma de México
↑ Salazar, M., Fedoroff, O. Y., Miller, J. M., Ribeiro, N. S., Reid, B. R. (1992). «The DNA strand in DNAoRNA hybrid duplexes is neither B-form nor A-form in solution». Biochemistry. 32 número=16: 4207-15. PMID 7682844. doi:10.1021/bi00067a007.
↑ Hermann, T. & Patel, D. J. (2000). «RNA bulges as architectural and recognition motifs». Structure 8 (3): R47–R54. PMID 10745015. doi:10.1016/S0969-2126(00)00110-6.
↑ Mikkola, S., Nurmi, K., Yousefi-Salakdeh, E., Strömberg, R. & Lönnberg, H. (1999). «The mechanism of the metal ion promoted cleavage of RNA phosphodiester bonds involves a general acid catalysis by the metal aquo ion on the departure of the leaving group». Perkin transactions 2: 1619-26. doi:10.1039/a903691a.
↑ Nudler, E. & Gottesman, M. E. (2002). «Transcription termination and anti-termination in E. coli». Genes to Cells 7: 755-68. PMID 12167155. doi:10.1046/j.1365-2443.2002.00563.x.
↑ Hansen, J. L., Long, A. M. & Schultz, S. C. (1997). «Structure of the RNA-dependent RNA polymerase of poliovirus». Structure 5 (8): 1109-22. PMID 9309225. doi:10.1016/S0969-2126(97)00261-X.
↑ Ahlquist, P. (2002). «RNA-Dependent RNA Polymerases, Viruses, and RNA Silencing». Science 296 (5571): 1270-73. PMID 12016304. doi:10.1126/science.1069132.
↑ Cooper, G. C., Hausman, R. E. (2004). The Cell: A Molecular Approach (3rd edición). Sinauer. pp. 261-76, 297, 339-44. ISBN 0-87893-214-3. OCLC 174924833 52121379 52359301 56050609.
↑ abc Wirta, W. (2006). Mining the transcriptome – methods and applications. Stockholm: School of Biotechnology, Royal Institute of Technology. ISBN 91-7178-436-5. OCLC 185406288.
↑ Rossi JJ (2004). «Ribozyme diagnostics comes of age». Chemistry & Biology 11 (7): 894-95. doi:10.1016/j.chembiol.2004.07.002.
↑ Nissen, P., Hansen, J., Ban, N., Moore, P. B., Steitz, T. A. (2000). «The structural basis of ribosome activity in peptide bond synthesis». Science 289 (5481): 920-30. PMID 10937990. doi:10.1126/science.289.5481.920.
↑ Grosjean, H. (2009) Nucleic acids are not boring long polymers of
only four types of nucleotides: a guided tour. DNA and RNA
Modification Enzymes: Structure, Mechanism, Function and
Evolution. Landes Biosciencies, Texas, USA, pp. 1–18.
↑ Kampers, T., Friedhoff, P., Biernat, J., Mandelkow, E.-M., Mandelkow, E. (1996). «RNA stimulates aggregation of microtubule-associated protein tau into Alzheimer-like paired helical filaments». FEBS Letters 399: 104D. PMID 8985176. doi:10.1016/S0014-5793(96)01386-5.
↑ Grosshans, H. & Filipowicz, W. 2008. Molecular biology: the expanding world of small RNAs. Nature, 451(7177):414-6 [1]
↑ Wu, L., Belasco, J.G. (enero de 2008). «Let me count the ways: mechanisms of gene regulation by miRNAs and siRNAs». Mol. Cell 29 (1): 1-7. PMID 18206964. doi:10.1016/j.molcel.2007.12.010.
↑ Matzke MA, Matzke AJM (2004). «Planting the seeds of a new paradigm». PLoS Biology 2 (5): e133|página=y|páginas=redundantes (ayuda). PMID 15138502. doi:10.1371/journal.pbio.0020133.
↑ Vázquez, F., Vaucheret, H., Rajagopalan, R., Lepers, C., Gasciolli, V., Mallory, A. C., Hilbert, J., Bartel, D. P. & Crété, P. (2004). «Endogenous trans-acting siRNAs regulate the accumulation of Arabidopsis mRNAs». Molecular Cell 16 (1): 69-79. PMID 15469823. doi:10.1016/j.molcel.2004.09.028.
↑ Watanabe, T., Totoki, Y., Toyoda, A., et al (mayo de 2008). «Endogenous siRNAs from naturally formed dsRNAs regulate transcripts in mouse oocytes». Nature 453 (7194): 539-43. PMID 18404146. doi:10.1038/nature06908.
↑ Sontheimer, E. J., Carthew, R. W. (julio de 2005). «Silence from within: endogenous siRNAs and miRNAs». Cell 122 (1): 9-12. PMID 16009127. doi:10.1016/j.cell.2005.06.030.
↑ Doran, G. (2007). «RNAi – Is one suffix sufficient?». Journal of RNAi and Gene Silencing 3 (1): 217-19. Archivado desde el original el 16 de julio de 2007.
↑ Pushparaj, P. N., Aarthi, J. J., Kumar, S. D., Manikandan, J. (2008). «RNAi and RNAa - The Yin and Yang of RNAome». Bioinformation 2 (6): 235-7. PMC 2258431. PMID 18317570.
↑ Hartig, J.V., Tomari, Y., Förstemann, K. (2007). «piRNAs--the ancient hunters of genome invaders.». Genes Dev. 21 (14). 1707-13. [2]
↑ Horwich, M. D., Li, C., Matranga, C., Vagin, V., Farley, G., Wang, P, & Zamore, P. D. (2007). «The Drosophila RNA methyltransferase, DmHen1, modifies germline piRNAs and single-stranded siRNAs in RISC». Current Biology 17: 1265-72. PMID 17604629. doi:10.1016/j.cub.2007.06.030.
↑ Girard, A., Sachidanandam, R., Hannon, G. J. & Carmell, M. A. (2006). «A germline-specific class of small RNAs binds mammalian Piwi proteins». Nature 442: 199-202. PMID 16751776. doi:10.1038/nature04917.
↑ Wagner, E. G., Altuvia, S., Romby, P. (2002). «Antisense RNAs in bacteria and their genetic elements». Adv Genet. 46: 361-98. PMID 11931231. doi:10.1016/S0065-2660(02)46013-0.
↑ Gilbert, S. F. (2003). Developmental Biology (7th edición). Sinauer. pp. 101-3. ISBN 0878932585. OCLC 154656422 154663147 174530692 177000492 177316159 51544170 54743254 59197768 61404850 66754122.
↑ Amaral, P. P., Mattick, J. S. (octubre de 2008). «Noncoding RNA in development». Mammalian genome : official journal of the International Mammalian Genome Society 19: 454. PMID 18839252. doi:10.1007/s00335-008-9136-7.
↑ Heard, E., Mongelard, F., Arnaud, D., Chureau, C., Vourc'h, C. & Avner, P. (1999). «Human XIST yeast artificial chromosome transgenes show partial X inactivation center function in mouse embryonic stem cells». Proc. Natl. Acad. Sci. USA 96 (12): 6841-46. PMID 10359800. doi:10.1073/pnas.96.12.6841.
↑ Djebali (2012). Landscape of transcription in human cells (489). pp. 101-108. Consultado el 13 de marzo de 2015.
↑ Tucker, B.J., Breaker, R.R. (2005). «Riboswitches as versatile gene control elements». Curr Opin Struct Biol 15 (3): 342-8. PMID 15919195. doi:10.1016/j.sbi.2005.05.003.
↑ Vitreschak, A.G., Rodionov, D.A., Mironov, A.A. & Gelfand, M.S. (2004). «Riboswitches: the oldest mechanism for the regulation of gene expression?». Trends Genet 20 (1): 44-50. PMID 14698618. doi:10.1016/j.tig.2003.11.008.
↑ ab Batey, R.T. (2006). «Structures of regulatory elements in mRNAs». Curr Opin Struct Biol 16 (3): 299-306. PMID 16707260. doi:10.1016/j.sbi.2006.05.001.
↑ Guerrier-Takada, C., Gardiner, K., Marsh, T., Pace, N. & Altman, S. (1983). «The RNA moiety of ribonuclease P is the catalytic subunit of the enzyme». Cell 35 (3 Pt 2): 849-57. PMID 6197186. doi:10.1016/0092-8674(83)90117-4.
↑ Berg, J. M., Tymoczko, J. L., Stryer, L. (2002). Biochemistry (5th edición). WH Freeman and Company. pp. 118-19, 781-808. ISBN 0-7167-4684-0. OCLC 179705944 48055706 59502128.
↑ Steitz, T. A., Steitz, J. A. (1993). «A general two-metal-ion mechanism for catalytic RNA». Proc. Natl. Acad. Sci. U.S.A. 90 (14): 6498-502. PMID 8341661. doi:10.1073/pnas.90.14.6498.
↑ Xie, J., Zhang, M., Zhou, T., Hua, X., Tang, L., Wu, W. (2007). «Sno/scaRNAbase: a curated database for small nucleolar RNAs and cajal body-specific RNAs». Nucleic Acids Res. 35: D183-7. PMID 17099227. doi:10.1093/nar/gkl873.
↑ Omer, A. D., Ziesche, S., Decatur, W. A., Fournier, M. J., Dennis, P. P. (2003). «RNA-modifying machines in archaea». Molecular Microbiology 48 (3): 617-29. PMID 12694609. doi:10.1046/j.1365-2958.2003.03483.x.
↑ Daròs, J. A., Elena. S. F., Flores, R. (2006). «Viroids: an Ariadne's thread into the RNA labyrinth». EMBO Rep. 7 (6): 593-8. PMID 16741503. doi:10.1038/sj.embor.7400706.
↑ Bell, G. 1997. The Basics of Selection. Springer, London, 378 pp. ISBN 412 055317
Enlaces externos
 Wikimedia Commons alberga una galería multimedia sobre ARN.
Wikimedia Commons alberga una galería multimedia sobre ARN.
 Wikcionario tiene definiciones y otra información sobre ARN.
Wikcionario tiene definiciones y otra información sobre ARN.


